


根据两项研究,大型语言模型(llm),即构建ChatGPT等生成式人工智能(genAI)工具的算法平台,在与企业数据库连接时非常不准确,并且变得不那么透明。
斯坦福大学的一项研究表明,随着法学硕士继续吸收大量信息,规模不断扩大,他们使用的数据的来源正变得越来越难以追踪。这反过来又使企业难以知道,它们是否能够安全地构建使用商业基因基础模型的应用程序,也使学者难以依赖这些模型进行研究。
斯坦福大学的研究称,这也使立法者更难制定有意义的政策来控制这项强大的技术,也让“消费者更难理解模型的局限性,或为造成的损害寻求赔偿”。
法学硕士(也被称为基础模型),如GPT、LLaMA和DALL-E,在过去一年中出现,并改变了人工智能(AI),使许多尝试它们的公司提高了生产力和效率。但这些好处伴随着沉重的不确定性。
斯坦福大学基金会模型研究中心的社会负责人Rishi Bommasani说:“透明度是公共问责制、科学创新和数字技术有效治理的必要前提。”“长期以来,缺乏透明度一直是数字技术消费者的一个问题。”
Bommasani指出,例如,欺骗性的在线广告和定价,拼车中不明确的工资做法,欺骗用户在不知情的情况下购买的黑暗模式,以及围绕内容审核的无数透明度问题,在社交媒体上创造了一个巨大的错误和虚假信息生态系统。
“随着商业(基金会模式)透明度的下降,我们在消费者保护方面面临着类似的威胁,”他表示。
例如,斯坦福大学的研究人员指出,OpenAI的名字中就有“开放”一词,但该公司明确表示,它不会对其旗舰模型GPT-4的大多数方面保持透明。
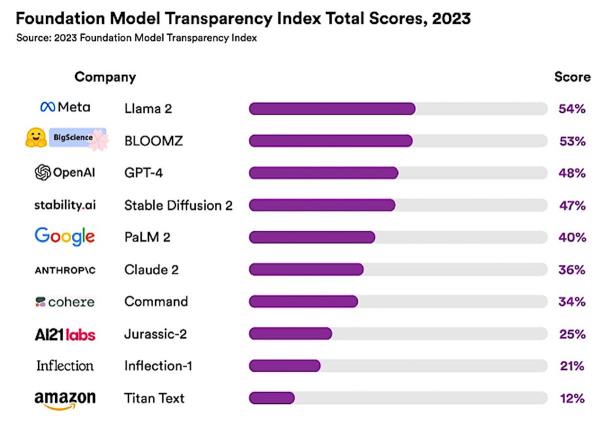
为了评估透明度,斯坦福大学召集了一个包括麻省理工学院和普林斯顿大学的研究人员在内的团队,设计了一个名为基础模型透明度指数(FMTI)的评分系统。它评估了100个不同的方面或透明度指标,从公司如何建立基础模型,如何工作,以及如何在下游使用。
斯坦福大学的研究评估了10位法学硕士,发现平均透明度得分仅为37%。LLaMA得分最高,透明度评级为52%;紧随其后的是GPT-4和PaLM 2,得分分别为48%和47%。
“如果没有透明度,监管机构甚至无法提出正确的问题,更不用说在这些领域采取行动了,”Bommasani说。
与此同时,根据网络安全和反病毒提供商卡巴斯基实验室的另一项调查,几乎所有的高级老板(95%)都认为员工经常使用基因人工智能工具,超过一半(53%)的人表示,基因人工智能工具正在推动某些业务部门的发展。该研究发现,59%的高管现在对与基因相关的安全风险深表担忧,这些风险可能危及公司的敏感信息,并导致对核心业务功能的控制丧失。
卡巴斯基首席安全研究员大卫?埃姆在一份声明中表示:“就像BYOD一样,genAI为企业提供了巨大的生产力效益,但尽管我们的研究结果显示,董事会高管们清楚地承认它在他们的组织中存在,但它的使用范围和目的却笼罩在神秘之中。”
法学硕士的问题不仅限于透明度;几乎从一年前OpenAI发布ChatGPT的那一刻起,这些模型的整体准确性就受到了质疑。
Juan Sequeda是data人工智能实验室的负责人。world是一家数据编目平台提供商,他说他的公司测试了连接到SQL数据库的法学硕士,并负责为公司特定问题提供答案。使用真实的保险公司数据,数据。world的研究表明,法学硕士对大多数基本业务查询的准确回复只有22%。对于中级和专家级的查询,准确率下降到0%。
缺少适合企业设置的文本到sql的基准测试可能会影响llm准确响应用户问题或“提示”的能力。
Sequeda表示:“法学硕士缺乏内部商业背景,这是准确性的关键。“我们的研究显示,在使用法学硕士特别是SQL数据库方面存在差距,SQL数据库是企业中结构化数据的主要来源。我假设其他数据库也存在这种差距。”
Sequeda指出,企业在云数据仓库、商业智能、可视化工具以及ETL和ELT系统上投资了数百万美元,所有这些都是为了更好地利用数据。能够使用法学硕士提出有关这些数据的问题,为改进关键绩效指标、指标和战略规划等流程开辟了巨大的可能性,或者创建全新的应用程序,利用深厚的领域专业知识创造更多价值。
这项研究主要集中在使用GPT-4的问题回答上,直接在SQL数据库上进行零提示。准确率?仅为16%。
基于企业数据库的不准确回应的净影响是对信任的侵蚀。“如果你向董事会提交的数字不准确,会发生什么?还是美国证券交易委员会?在每种情况下,成本都会很高。”
llm的问题在于,它们是统计和模式匹配机器,根据之前出现的单词来预测下一个单词。他们的预测是基于对整个开放网络内容的观察模式。根据Sequeda的说法,因为开放网络本质上是一个非常大的数据集,LLM将返回看起来非常合理但也可能不准确的东西。
另一个原因是,这些模型只能根据它们所看到的模式做出预测。如果他们没有看到特定于您的企业的模式,会发生什么?嗯,不准确性增加了。”
Sequeda继续说道:“如果企业试图在没有解决准确性的情况下大规模实施法学硕士,那么这些计划将会失败。”“用户很快就会发现他们不能信任llm,并停止使用它们。多年来,我们在数据和分析领域也看到了类似的模式。”
当通过企业SQL数据库的知识图表示提出问题时,llm的准确率提高到54%。Sequeda表示:“因此,投资知识图谱可以为法学硕士驱动的问答系统提供更高的准确性。“目前还不清楚为什么会发生这种情况,因为我们不知道LLM内部发生了什么。
Sequeda继续说道:“我们所知道的是,如果你在包含关键业务上下文的知识图谱中给法学硕士一个本体映射的提示,那么准确率是不这样做的三倍。”“然而,重要的是要问自己,‘足够准确’是什么意思?”
为了提高法学硕士做出准确回应的可能性,公司需要拥有“强大的数据基础”,也就是Sequeda等人所说的人工智能就绪数据;这意味着数据被映射到知识图中,以提高响应的准确性,并确保其可解释性,“这意味着您可以让法学硕士展示其工作。”
提高模型准确性的另一种方法是使用小型语言模型(slm),甚至是特定于行业的语言模型(ilm)。Sequeda表示:“我可以预见,未来每家企业都将利用一些特定的法学硕士,每个法学硕士都将针对特定类型的问答进行调整。”然而,方法仍然是一样的:预测下一个单词。这个预测可能很高,但预测总是有可能是错误的。”
Sequada表示,每家公司还需要确保监督和治理,以防止敏感和专有信息被不可预测的模型置于风险之中。



