美国能源部橡树岭国家实验室的一组计算科学家已经生成并发布了规模空前的数据集,这些数据集提供了超过1000万个有机分子的紫外可见光谱特性。了解分子如何与光相互作用对于揭示其电子和光学特性至关重要,这反过来又在太阳能电池或医疗成像系统等产品中具有潜在的光活性应用。
ORNL团队利用橡树岭领导计算设施的高性能计算资源,进行量子化学计算,生成庞大的数据集。对于每一种有机分子,研究小组用不同的近似值进行原子材料建模计算,以计算不同的感兴趣的激发态特性。该团队的研究结果发表在《科学数据》杂志上。
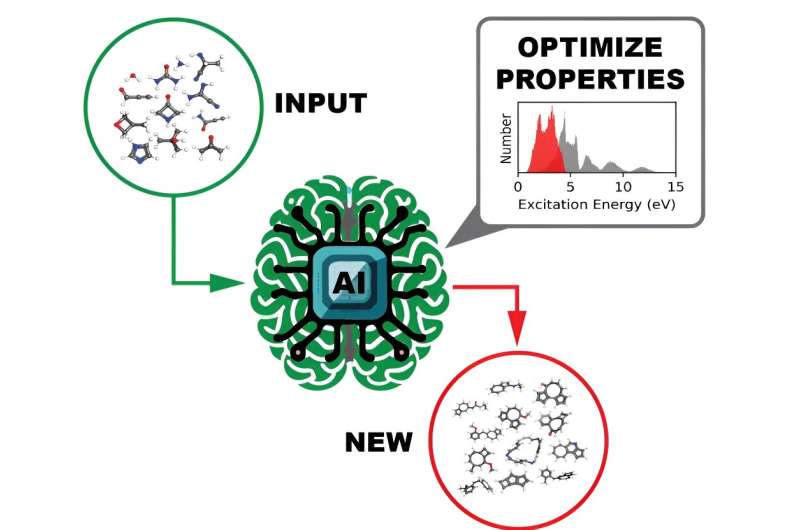
开源数据集的最终用途是训练一个深度学习模型,以识别具有定制光电和光反应性特性的分子,这种方法比目前的方法更快,更容易进行。
ORNL计算科学与工程部的数据科学家Massimiliano Lupo Pasini说:“使用深度学习模型进行分子设计是必不可少的,因为必须探索寻找这些分子的化学空间非常大。”
“实验和现有的第一性原理计算都是基于确定物质和能量如何在亚原子水平上相互作用的物理定律,由于不同的原因,它们根本负担不起。实验是劳动密集型的,第一性原理计算可以轻易地击败超级计算设备。但深度学习模型为克服这些障碍提供了非常有前途的工具。”
当ORNL计算化学和纳米材料科学小组的负责人Stephan Irle发现分子的紫外可见光谱是用DL模型预测的有用属性时,该项目开始了。
建立一个足够复杂的深度学习模型来识别理想的分子特性,需要用大量的数据来训练它,这些数据可以探索化学空间的所有不同区域。收集的数据越多,在其上训练的深度学习模型就越能达到有效运行所必需的鲁棒性和泛化性。然而,为可扩展的深度学习收集如此大量的科学数据可能会带来数据流问题,特别是在OLCF(位于ORNL的美国能源部科学办公室用户设施)等拥有多个用户的设施中。
“生成大量数据时面临的一个挑战是,需要管理的文件数量急剧增加。如果管理不当,如此大量的数据可能会危及并行文件系统的功能,而并行文件系统是最先进的高性能计算设施的重要组成部分,”Lupo Pasini说。
为了应对这一挑战,Lupo Pasini与ORNL计算机科学家Kshitij Mehta合作开发了一种可扩展的工作流软件,以确保由量子力学代码生成的文件得到妥善处理,而不会对文件系统造成压力,例如OLCF的Orion,这是一种共享资源,用于处理超级计算机系统上数据的输入、输出和存储。
作为概念验证测试,该团队生成了GDB-9-Ex数据集,其中包含96,766个由碳、氮、氧和氟组成的分子,最多有9个非氢原子。结果表明,所设计的工作流程是有效的,深度学习训练能够准确地预测出紫外可见光谱中最相关峰的位置和强度。
从最初的成功开始,研究小组用ornl_aaid - ex数据集扩大了其体积,该数据集包含由碳、氮、氧、氟和硫组成的10,502,917个分子,最多有71个非氢原子。Irle团队的博士后研究员Pilsun Yoo开发了分析结果数据集的工具。
描述分子激发模式的紫外-可见光谱,被计算了超过1000万个分子中的每一个。这一信息揭示了需要什么样的光频率才能锁定一个分子并破坏化合物的某些键。
为每个分子计算的另一个有趣的性质是HOMO-LUMO间隙——最高已占据分子轨道和最低未占据分子轨道之间的能量间隙——它可靠地测量了分子的稳定性。有了这些信息,DL模型可以有效地筛选数据,以识别有前途的分子,用于不同的潜在用途。
事实上,ORNL的Lupo Pasini和他的团队,包括机器学习的计算科学家Pei Zhang和HPC数据研究科学家Jong Youl Choi,正在开发这样一个深度学习模型:HydraGNN。
“HydraGNN架构采用原子结构,将其转换为图形,然后试图预测第一原理代码将产生的输出。它是昂贵的第一性原理计算的替代模型,”Lupo Pasini说。
HydraGNN在数据集上的训练结果及其分子发现将在即将发表的论文中详细介绍。